When I first took a pass at writing a Framework many years ago, I thought I was so clever being able to use reflection to solve common problems. Then I learned about Expression Trees and more fun but difficult to maintain concepts. At one point I sat down and said to myself, will anyone else really be able to add to this or understand this later? For the most part maybe not.
Then after stumbling around Aspect Oriented Programming with Post Sharp and Run-time Weaving with Unity (container), I landed on a simpler solution. Conventional Programming.
Entity Framework use to come with *.edmx that used *.tt (t4) files to generate code. Some edits in the t4 model generator could enable custom interfaces to be applied to entities, and with a lookup those interfaces could be found dynamically. This meant that by simply defining an interface to used as a convention, during database first generation those interfaces could be applied to your entities automatically.
Your data access layer then could work with interfaces to apply common rules to based off of those conventions. It worked but wasn’t great. Mainly because editing a *.tt file was pretty painful and there wasn’t many tools out there to help. Also *.edmx were a nightmare.
Then EFCore came around and removed *.edmx all together and no longer used *.tt files for generation, so I had to start over with this.
Warning
I want to be clear. How I got everything here to work is using parts of EFCore that is not apart of the same API backwards compatibility standards. This means at any time, EFCore could remove the API I used to achieve this.
What it does not mean, is that your code will stop working. Upgrading to the next version might cause an headache.
I’m using public classes in namespaces *.Internals which will provide an EF1001 Compiler Warning. This warning should also be shown to any user attempting to use my libraries.
Entity Scaffolding
I’m introducing a new Open Source library called Entity Scaffolding, because I’m not as creative with naming as others.
I’m going to cover a few aspects of how this works in my blog to highlight some of the power of said solution. It is an extremely simple library. Really doesn’t have much code in it, but it is pretty powerful.
Opening the box, using Adventure Works
What’s a .NET POC without Adventure Works? So, I recommend first let’s setup Adventure Works and use the Default Conventions provided by Entity Scaffolding to see what it can do.
Quick Teaser
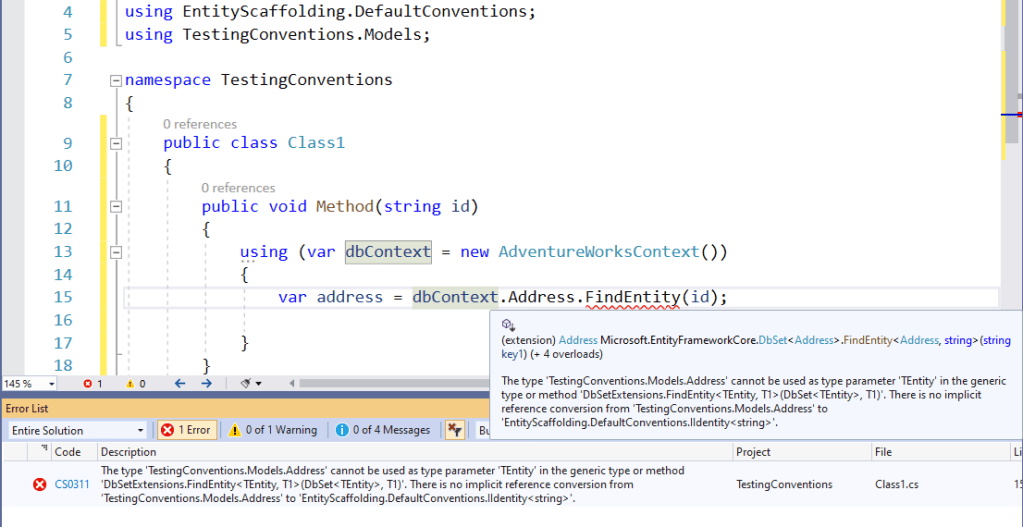
As a quick teaser before we get started, this is the EF Generated Code for the Address POCO:
using System;
using System.Collections.Generic;
using EntityScaffolding.DefaultConventions;
namespace TestingConventions.Models
{
public partial class Address: IRowguid, IUpdateTracker, IIdentity<int>
{
public Address()
{
BusinessEntityAddress = new HashSet<BusinessEntityAddress>();
SalesOrderHeaderBillToAddress = new HashSet<SalesOrderHeader>();
SalesOrderHeaderShipToAddress = new HashSet<SalesOrderHeader>();
}
[PrimaryKey]
public int AddressId { get; set; }
public string AddressLine1 { get; set; }
public string AddressLine2 { get; set; }
public string City { get; set; }
public int StateProvinceId { get; set; }
public string PostalCode { get; set; }
public Guid Rowguid { get; set; }
public DateTime ModifiedDate { get; set; }
public virtual StateProvince StateProvince { get; set; }
public virtual ICollection<BusinessEntityAddress> BusinessEntityAddress { get; set; }
public virtual ICollection<SalesOrderHeader> SalesOrderHeaderBillToAddress { get; set; }
public virtual ICollection<SalesOrderHeader> SalesOrderHeaderShipToAddress { get; set; }
}
}
Note: Additional interfaces were added, using statements updated, and the Primary Key property tagged with an Attribute.
Adventure Works
If you don’t already have an Adventure Works database installed you can download it from Microsoft: Adventure Works 2017
Project Setup
Create a new Console APP or Class Library using .NET Core 3.0.
In your Package Manager Console run the following commands:
Assuming you are using Sql Server you can run this command as well. If you are using a different database type you will have to install the respective package.
Create a new class in the project called DesignTimeServices with the following code.
using EntityScaffolding;
using EntityScaffolding.DefaultConventions;
using Microsoft.EntityFrameworkCore.Design;
using Microsoft.EntityFrameworkCore.Scaffolding.Internal;
using Microsoft.Extensions.DependencyInjection;
namespace <YourNameSpace>
{
public class DesignTimeServices : IDesignTimeServices
{
public void ConfigureDesignTimeServices(IServiceCollection serviceCollection)
{
serviceCollection.AddSingleton(new UseDefaultConventions());
serviceCollection.AddSingleton<ICSharpEntityTypeGenerator, ConventionEntityTypeGenerator>();
}
}
}
If the Internal namespace or ICSharpEntityTypeGenerator interface is not resolved, you will have to manually add the Microsoft.EntityFrameworkCore.Design.dll to your project.
Right Click “Dependencies” under you project and select “Add Reference”.
Browse to C:\Users\<YourUsername>\.nuget\packages\microsoft.entityframeworkcore.design\3.0.1\lib\netstandard2.1
And select Microsoft.EntityFrameworkCore.Design.dll
Generating Models
Run the following command in the Package Manager Console:
You of course may have to edit the connection string to your specific database.
Done
Now if you browse your models you will see that interfaces and attributes have been added to the models they apply to.
These conventions are defined in EntityScaffolding.DefaultConventions but are not required. By removing that package and the following line from DesignTimeServices, only conventions you defined will be used.
Re-run the Scaffold-DbContext command but with ‘-force’.
If you open the Person Entity, you will now see the IPerson interface was automatically added the the Entity.
Conclusion
With the Entity Scaffolding Framework, you can quickly and easily apply custom conventions to your entities during scaffolding. In future posts I’ll cover some additional aspects of the framework, specifically how to additional code, and cover scenarios how you can use entities with conventions.
Although I only have a version out for 3.0.1, I have tested with 3.1.0 and it still works exactly the same. I plan on releasing nuget packages that align with the EFCore versions to avoid confusion.
Check out Part 2 that covers an updated Find method that is Type Specific: Part 2 Fixing Find
If you already hate the Repository Pattern, I get it. You had a bad experience with it. Implementing Repos over and over again has no benefits. I 100% agree. I although have not have had the same experience, as I do not recommend that approach. I focus on a zero rework implementation. People don’t give Repositories the benefit of a doubt, as their previous implementations of it had problems. Here I’ll suggest a method of having generic repositories, with plug-in customization, and expanding past the IRepository<T> interface without having to implement the class Repository.
My baseline problem is, did you consider this method before discounting the pattern? I know there is a lot of hate for the pattern. The reason why I’m even making this post is how divergent my implementation was from what the “Gurus” are considering as a bad implementation. If I have had a limited development overhead, and have successfully used the pattern, where a “Guru” had a failure, who’s wrong?
When I say success, I mean 250 developers, 500 million dollar project, 5+ million lines of code, 100k concurrent users. Then though this pattern was more acceptable, and that is why where my debate lies. I posed the question to myself today, should I still be recommending the Repository Pattern for new development? (Got lucky finally a green-field) So, I started reading arguments on various reason not to.
After reading a half dozen blogs, I didn’t have a conclusion but arrived at is everyone just doing it poorly? So let’s talk about common problems in implementations of the Repository Pattern and how we can solve them. At the end, let me know if you still think it is an Anti-Pattern.
Common Mistakes
If you ask 10 developers to design a Repository Pattern from scratch, you would get 10 different patterns. That is the biggest problem with the Repository Pattern. Its such a simple concept, but developers create artificial constraints in their design. Lets go through some common mistakes.
Jon Smith pointed me to MSDN’s implementation of the Repository and Unit Of Work Pattern after reading this post. I personally feel lucky to never have been constrained by that mess. This is probably where most bad practices come from. Their samples definitely are problematic and only in their side notes do they briefly address the issues.
Mistake #1 – Not using generics
Hold on if you already know the problem with using a simple approach to generics.Mistake #3 – Extensibility Points addresses those issues.
So if you were to go into an interview and were asked what is the Repository Pattern, the answer CRUD is acceptable. So at a developer’s first pass at creating a Repository it could look like this.
public interface IPersonRepository
{
void InsertPerson(Person person);
void UpdatePerson(Person person);
void DeletePerson(Person person);
Person GetById(int personId);
}
Then you look at the database, and it’s 200 tables and you think, “I’m smart I’ll make it generic!”
public interface IRepository<TEntity> where TEntity : class
{
void Insert(TEntity entity);
void Update(TEntity entity);
void Delete(TEntity entity);
//Cannot do this anymore since keys can be different per table.
//TEntity GetById(int id);
//So you do this
TEntity Find(params object[] keys);
//Might as well add this as well.
IQueryable<TEntity> Query { get; }
}
Mistake #2 – Not using generics enough
But for some reason people stop at the interface with their generics and end up writing this next.
public class PersonRepository : IRepository<Person>
{
//Hard coded
}
We although can move the generic into the implementation, like this:
public /*sealed*/ class EntityRepository<TEntity> : IRepository<TEntity>
where TEntity : class
{
protected /*private*/ TDbContext Context { get; private set; }
protected /*private*/ DbSet<TEntity> Set => Context.Set<TEntity>();
public EntityRepository(TDbContext dbContext)
{
Context = dbContext;
}
public IQueryable<TEntity> Query => Set;
public TEntity Find(params object[] keys)
{
return Set.Find(keys);
}
public void Insert(TEntity entity)
{
var entry = Context.Entry(entity);
if (entry.State == EntityState.Detached)
Set.Add(entity);
}
public void Delete(TEntity entity)
{
var entry = Context.Entry(entity);
if (entry.State == EntityState.Detached)
Set.Attach(entity);
Set.Remove(entity);
}
public void Update(TEntity entity)
{
var entry = Context.Entry(entity);
if (entry.State == EntityState.Detached)
Set.Attach(entity);
entry.State = EntityState.Modified;
}
}
Note: Do not make this class abstract, even consider making it sealed.
Bonus: You can put IRepository in Framework.Data.dll and EntityRepository in Framework.Data.EF6.dll or Framework.Data.EFCore.dll. This will make it so classes that use IRepository do not have to have a reference to EF.
Looks great. We can use a Container to resolve IRepository<Person> to EntityRepository<MyContext, Person> and life is good. Development can do CRUD on Repositories, and don’t need to explicitly create them.
Side Note: The first time I showed the above class to a Senior Architect seven years ago, he said to me: “Is this some type of dictionary? I expect with two generics it would be a dictionary.” It is interesting that people don’t quite get the full use of generics.
Mistake #3 – Extensibility Points
All is good in the world, until day two of development and someone needs to do something custom. So this happens:
public class EntityRepository<TEntity> : IRepository<TEntity>
where TEntity : class
{
// Sections removed for brevity
protected virtual void Inserting(TEntity entity)
{
//Template method
}
protected virtual void Inserted(TEntity entity)
{
//Template method
}
public void Insert(TEntity entity)
{
Inserting(entity);
var entry = Context.Entry(entity);
if (entry.State == EntityState.Detached)
Set.Add(entity);
Inserted(entity);
}
}
public interface IPersonRepository : IRepository<Person>
{
IEnumerable<Person> GetPeopleByName(string firstName, string lastName);
}
public class PersonRepository : EntityRepository<MyContext, Person>, IPersonRepository
{
protected override void Inserting(TEntity entity)
{
if(!CurrentUser.IsAdmin)
{
throw new SecurityException();
}
}
public IEnumerable<Person> GetPeopleByName(string firstName, string lastName)
{
return Query.Where(p => p.FirstName == firstname && p.LastName == lastName);
}
}
Now we are kind of back to where we started. Custom interfaces resolving to custom classes, but now we have a little bit of reusable code.
First, don’t create custom interfaces per table. There is no need, use extension methods. Hopefully, you’re going to use this for something more useful than the example though.
public static class PersonRepositoryExtensions
{
public static IQueryable<Person> GetPeopleByName(this IRepository<Person> repository,
string firstName, string lastName)
{
return repository.Query.Where(p => p.FirstName == firstname && p.LastName == lastName);
}
}
You can even take this a bit further if required and apply a convention.
public interface INamedIndividual
{
string FirstName { get; set; }
string LastName { get; set; }
}
//Apply the interface to entity via partials
public partial Person : INamedIndividual
{
}
public partial Employee : INamedIndividual
{
}
public static class IndividualRepositoryExtensions
{
public static IQueryable<TIndividual> GetByName<TIndividual>
(this IRepository<TIndividual> repository, string firstName, string lastName)
where TIndividual : INamedIndividual
{
return repository.Query.Where(p => p.FirstName == firstname && p.LastName == lastName);
}
}
Now we can add queries to specific generics based off of class or interface. We do not need to create custom interfaces or inherited classes, and it works quite nice.
Side Note: Did you know you could create a constrained generic extension method? I don’t blame you if you didn’t. They work surprisingly well; even with intelli-sense.
Going back the the template method pattern above, did you notice the bug? Attached entities could bypass that check. This is where to me things get a bit more complicated. What I do is a Rules Service, in light of a better name. I’ll talk about that soon.
Mistake #4 – Not sharing the context
If every Repository you create, you create a new DbContext for that Repository, the scope of work you can do is limited by the Repository. You need to come up with a mechanism for multiple Repositories to use the same context. The Unit Of Work pattern can be used to allow this. Imagine the following example.
Sharing the context between the two Repositories means one payload of data will be sent over to the database. Additionally you could join between the two queries on the repository and execute one query in SQL. Not having a shared context limits what you can do, and causes performance issues.
Adding Unit Of Work Pattern
Notice I also never defined a Save or Submit method. The Unit Of Work Pattern defines the beginning and end of a transaction, and to me is also responsible for defining where Save actually occurs. So we can define UnitOfWork as such.
Core level abstractions
First in my Unit Of Work I want to be able to event back when it is disposed. Pretty much we need to notify the UnitOfWorkManager the scope has ended to remove the UnitOfWork.
public interface IDisposing : IDisposable
{
event EventHandler Disposing;
}
public abstract class Disposable : IDisposing
{
protected virtual void Dispose(bool disposing)
{
}
public void Dispose()
{
Disposing?.Invoke(this, new EventArgs());
Dispose(true);
GC.SuppressFinalize(this);
}
public event EventHandler Disposing;
}
Unit of Work Interface
The Unit Of Work interface is simple itself. It can Submit and Dispose. In the past I’ve had Submit on the Repositories, which really didn’t make sense. The Repositories all shared the context, so saving one would save all. It turned into a mess where developers thought they had to save multiple times.
public static class UnitOfWorkManager : IUnitOfWork
{
[ThreadStatic] \\[AsyncLocal]
private static IUnitOfWork _unitOfWork;
private Func<IUnitOfWork> _unitOfWorkFunc;
public UnitOfWorkManager(Func<IUnitOfWork> unitOfWorkFunc)
{
_unitOfWorkFunc = unitOfWorkFunc;
}
public IUnitOfWork CurrentUnitOfWork => _unitOfWork;
public IUnitOfWork Begin()
{
if (_unitOfWork != null)
{
return _unitOfWork;
}
var unitOfWork = _unitOfWorkFunc();
if (unitOfWork == null)
{
throw new InvalidOperationException("Could not resolve Unit Of Work.");
}
unitOfWork.Disposing += UnitOfWorkDisposing;
_unitOfWork = unitOfWork;
return _unitOfWork;
}
private void UnitOfWorkDisposing(object sender, EventArgs e)
{
if (sender != _unitOfWork)
{
throw new InvalidOperationException("Sender for ending unit of work mis-matched.");
}
_unitOfWork = null;
}
}
You can use a container as well to have a scoped instance of Unit Of Work, that is fine. This example is managing the scope of it for you. This is important as it will use only one instance of a context between all the repositories used in your Unit Of Work.
The Thread Static \ Async Local instance, will keep all calls in the scope using the same Unit Of Work which uses the same DbContext. The scope is specifically where you want to use it, and isn’t too large or small.
Entity Unit Of Work
The next thing we need to do, is make a specific Unit Of Work for EF. Here are going to implement Submit and Dispose. One additional method is needed, which is to store and create the context that is being used.
public class EntityUnitOfWork : Disposable, IUnitOfWork
{
private DbContext _context;
private Func<DbContext> _contextFunc;
public bool HasEnded { get; private set; }
public EntityUnitOfWork(Func<DbContext> contextFunc)
{
_contextFunc = contextFunc;
}
public TDbContext GetContext<TDbContext>() where TDbContext : DbContext
{
if (HasEnded)
{
throw new ObjectDisposedException("Unit of Work has been disposed.");
}
return (TDbContext)(_context ??= _contextFunc());
}
public void Submit()
{
if (HasEnded)
{
throw new ObjectDisposedException("Unit of Work has been disposed.");
}
if(_context != null)
{
RulesService.ApplyInsertRules(_context.Changes(EntityState.Added));
RulesService.ApplyDeleteRules(_context.Changes(EntityState.Modified));
RulesService.ApplyUpdateRules(_context.Changes(EntityState.Deleted));
_context.SaveChanges();
}
}
protected override void Dispose(bool disposing)
{
if (!HasEnded)
{
_context?.Dispose();
HasEnded = true;
}
base.Dispose(disposing);
}
}
public static class DbContextExtensions
{
public static IEnumerable<object> Changes(this DbContext context, EntityState state)
{
return context.ChangeTracker.Entries().Where(x => x.State == state).Select(x => x.Entity);
}
}
I added an extension method for the DbContext to get the changes, and also send those changes to a RulesService. This is where we will be applying any custom rules per entity type or convention. The ChangeTracker right before Save Changes is the only way to find all changes. The CRUD Repository methods can have attached properties on the entities and the logic could be skipped.
One thing to note is, if lets say a Delete Rule Inserts an entity, the insert rule could be skipped. If this is an important factor for you, you might want to re-work this method. You could deep clone the changeset and run of the rules until the changeset doesn’t have and differences.
Additionally, for simplicity I didn’t account for having multiple DbContexts. One could add logic to allow for these feature. I have in the past but it was never used.
Updating the Repository
One more thing we would need to do to make this work, and that is to update our EntityRepository to use the shared context from the Unit Of Work. The UnitOfWorkManager although just uses a IUnitOfWork and doesn’t know about the context. So some casting is required to get the specific type. You could make this a bit more elaborate of course, but this would work just fine.
public class EntityRepository<TEntity> : IRepository<TEntity>
where TEntity : class
{
private DbContext _context = ((EntityUnitOfWork)unitOfWorkManagerFunc.CurrentUnitOfWork).GetContext();
protected TDbContext Context => _context;
protected DbSet<TEntity> Set => Context.Set<TEntity>();
private Func<IUnitOfWorkManager> _unitOfWorkManagerFunc;
public EntityRepository(Func<IUnitOfWorkManager> unitOfWorkManagerFunc)
{
_unitOfWorkManagerFunc = unitOfWorkManagerFunc;
}
//Rest is removed for brevity
}
Rules Outside of the Repository Pattern
Its pretty apparent that there is a need for rules to be applied for Repositories. Under my outline though, there really isn’t a way to do that. That is based off of design. The problem is if there was a Repository for every table that is too many, if there is a Repository for every concern it doesn’t make sense. Making a hierarchy based off of different rules doesn’t work.
public class AuditableRepository<TDbContext, TEntity> : EntityRepository<TDbContext, TEntity>
{
}
public class SoftDeleteRepository<TDbContext, TEntity> : EntityRepository<TDbContext, TEntity>
{
}
public class AuditableAndSoftDeleteRepository<TDbContext, TEntity> : SoftDeleteRepository?...
So the next logical step would be to centralize that logic, and you could have something like this:
A paradigm like this would separate the logic out, and allow for tables to use multiple rules. It although is just one step away from a Custom Repository free solution.
My solution has been a Rules Service, this can be a Event Aggregator, a Functional Paradigm or something custom. It’s up to you on how to define this. One recommendation is to account for variance, so rules can be applied based off of convention. Here is a very simple example.
public static class RulesService
{
private static readonly List<Action<object>> DeleteRules = new List<Action<object>>();
public static void AddDeleteRule(Action<object> deleteRule)
{
DeleteRules.Add(deleteRule);
}
public static void AddDeleteRule<TEntity>(Action<TEntity> deleteRule)
{
DeleteRules.Add(x =>
{
if (x is TEntity entity)
{
deleteRule(entity);
}
} );
}
public static void ApplyDeleteRules(IEnumerable<object> deleting)
{
foreach (var entity in deleting)
{
foreach (var rule in DeleteRules)
{
rule(entity);
}
}
}
}
This is shown for simplicity. The ones I have designed in the past have been a bit more complicated. Using Expression Trees to compile custom statements per type to squeeze that last bits of performance out.
One additional place we can apply the Rules Service is in the Repository for queries.
public class EntityRepository<TEntity> : IRepository<TEntity>
where TEntity : class
{
// Sections removed for brevity
public IQueryable<TEntity> Query => Set.ApplyReadRules();
public TEntity Find(params object[] keys)
{
var entity = Set.Find(keys);
return RulesService.CanRead(entity) ? entity : null;
}
}
Note: Read Rules should be Expressions so they can be applied to queries and compiled for Finds.
Where does this leave us?
Looking at the Repository Pattern as outline. There is zero development outside of Framework level reusable components for each repository. Creating a repository is as simple as configuring your container, or adding the entity with an auto-config container.
Our custom behavior can still be defined as extensions which also can be applied conventionally instead of just off of the entity.
Our custom rules are defined outside the scope of the Repositories, and can be added in based off of how we setup our Rules Service. Again this can work off of convention and have zero development cost when adding a new entity.
Testing
Personally I find using Moq on every unit test becomes a bit overwhelming. I also find in-memory test databases limited. I often find creating a Testing or a TestHelper API that allows data setup and assertions can simplify testing greatly. For example this is pretty simple:
using(var mock = DataMocking.Start())
{
var person = new Person
{
FirstName = "Ada",
LastName = "Lovelace"
};
mock.AddTestData(person);
Business.DoOperation();
CollectionAssert.AreEquivalent(new [] { person }, mock.DeletedItems<Person>());
}
Here DataMocking.Start() is re-configuring the container used by the framework. Instead of returning a EntityUnitOfWork and a EntityRepository it will return a MockUnitOfWork and a MockRepository. The returned mock object is a cache of all the used data objects which the MockRepository will use. Disposing of the mock, clears out the data used for the test.
The design laid out here doesn’t have the problems that usually are stated. This leaves me thinking, is Repositories really a bad pattern or were there just a ton of bad implementations of it? What are your thoughts now that I outlined more around how to implement this is a different way? Is this still wrong? Maybe, but personally I’m having a hard time separating naysayers from valid opinions.
Just be clear this is a thought exercise for me. I am not leaning one way or the other. It’s just hard for me to accept other people’s failures as a reason, when I’ve been successful with minor tweaks.
I have been reading Wikipedia and Unicode for too long. I found this path pretty interesting. I assume individuals who went to school for Linguistics might already know this, and I also assume I can be completely wrong. One way to find out I guess.
Logographic Script
It seems most written language starts as Pictograms, physical representations of objects drawn. The most famous is the Egyptian Hieroglyphs dated back to 2690 BC.
Eventually these elaborate images turn into strokes on clay with a reed stylus. The earliest version of this can be dated back to 2600 BC. This is referred to as Cuneiform.
The Proto-Sinaitic alphabet was created in 1900 BC which was derived from Egyptian Hieroglyphs and Akkadian Cuneiform. This was followed by the Phoenician alphabet in 1050 BC. Both of these alphabets did not have any vowels, and vowels were implied.
The fish turned back into a Pictogram. Coincidentally, later ichthus went on to turn back into a Pictogram of a fish as a symbol for Jesus which you see as a sticker on the back of cars.
ἰχθύςGreek [ichthus]: Fish
Next Up: How to turn your Coffee into a Fish (maybe)
I will explore the word Fish in Asian languages next.
If you didn’t already setup Entity Scaffolding, please checkout Part 1 before continuing.
DbSet.Find(Object[]) Although a powerful method, it can cause some problems. Primarily, the lack of compile time checking of the arguments. Usually, there is a bit of double checking during initial use, and then god forbids someone changes the keys. You can have some hidden bugs on your hands.
Worst yet if you have two int primary keys, it wasn’t always straight forward the order of the keys. Sometimes it is even possible for EF to shift the keys and not inform you.
I always despised the Find method, it is the rare Object[] in a modern framework. It always seemed that there was a better way. As crazy as it sounds, it kept me up at night.
Then one night a few years ago I did figure it out…
IIdentity<T1,…,Tx>
The first thing is the definition of a few generic Identity interfaces. (Already done in EntityScaffolding.DefaultConventions)
namespace EntityScaffolding.DefaultConventions
{
public interface IIdentity<T> { }
public interface IIdentity<T1, T2> { }
public interface IIdentity<T1, T2, T3> { }
public interface IIdentity<T1, T2, T3, T4> { }
public interface IIdentity<T1, T2, T3, T4, T5> { }
}
Note: I have in the past had the Identity interfaces define a method returning a tuple composed of the keys, but haven’t found much use for such a method.
Then during scaffolding, we can apply these interfaces to our entities automatically.
public partial class EmployeeDepartmentHistory: IIdentity<int, DateTime, short, byte> { /***/ }
public partial class EmployeePayHistory: IIdentity<int, DateTime> { /***/ }
public partial class Address: IIdentity<int> { /***/ }
FindEntity Extension Method
Depending on your data layer you can add FindEntity Extension Methods to either DbSet or your IRepository. EntityScaffolding.DefaultConventions define these extensions methods off of DbSet for you.
public static class DbSetExtensions
{
public static TEntity FindEntity<TEntity, T1>(this DbSet<TEntity> set, T1 key1)
where TEntity : class, IIdentity<T1>
{
return set.Find(key1);
}
public static TEntity FindEntity<TEntity, T1, T2>(this DbSet<TEntity> set, T1 key1, T2 key2)
where TEntity : class, IIdentity<T1, T2>
{
return set.Find(key1, key2);
}
//And so forth
}
Using the FindEntity Method will cause compile time exceptions to occur when the improper types are used. This should help avoid some bugs.
Unfortunately at the time of writing this, there is an intelli-sense bug in the .NET Core compiler for these methods. It is just creating a less than ideal usage of the methods. Ideally the constants should limit the intelli-sense options, but currently just a compile error is shown. Hopefully, this is resolved shortly.
PrimaryKeyAttribute
Another aspect is the PrimaryKeyAttribute. With the Default Conventions in Entity Scaffolding, the PrimaryKeyAttribute will be added to the properties along with their index.
public partial class BusinessEntityAddress : IIdentity<int, int, int>
{
[PrimaryKey(1)]
public int BusinessEntityId { get; set; }
[PrimaryKey(2)]
public int AddressId { get; set; }
[PrimaryKey(0)]
public int AddressTypeId { get; set; }
/***/
}
First, this helps developers know which value corresponds with which argument index.
Second during writing this post, I reevaluated the shifting index problem. Although not released just yet, I’m adding support to inform the developer that indexes have shifted during scaffolding.
This should help the developers know when indexes were shifted. My initial pass at these warnings, only display the messages if a compile error won’t be shown. IE: The types are the same. I need to update it to cover implicit casts, such as Int32 and Int16 as so forth.
The way I am accomplishing these warnings is by parsing the existing assembly during scaffolding, and looking for the PrimaryKey attributes. From that information I can determine if a change has occurred.
Conclusion
Still a little bit of development to do, and a little bit of waiting for Roslyn to fix a bug.
Every C# developer knows there are classes and structs, and at least once in an interview was asked about boxing. Additionally, they understand the concepts of mutable and immutable. This is where this puzzle will focus today.
Note: Scroll selectively to not spoil the results.
Lets jump into it.
class Program
{
static void Main(string[] args)
{
var c = new Counter();
var d = new Dictionary<string, Counter>();
d["hello"] = c;
c.Increment();
Console.WriteLine(c.Count);
Console.WriteLine(d["hello"].Count);
d["hello"].Increment();
Console.WriteLine(c.Count);
Console.WriteLine(d["hello"].Count);
Console.ReadLine();
}
}
public class Counter
{
public int Count { get; private set; }
public void Increment()
{
Count += 1;
}
}
We have a class with an int property. A method that increments it. In the function we are putting an instance of it into a dictionary, and the incrementing it both from the variable and from the dictionary indexer.
What do you expect the output to be?
Space to avoid spoilers.
1 1 2 2 – Nothing unexpected, but you know what is next…
class Program
{
static void Main(string[] args)
{
var c = new Counter();
var d = new Dictionary<string, Counter>();
d["hello"] = c;
c.Increment();
Console.WriteLine(c.Count);
Console.WriteLine(d["hello"].Count);
d["hello"].Increment();
Console.WriteLine(c.Count);
Console.WriteLine(d["hello"].Count);
Console.ReadLine();
}
}
public struct Counter
{
public int Count { get; private set; }
public void Increment()
{
Count += 1;
}
}
Let’s change Counter to a struct. What do you expect to happen now?
Space to avoid spoilers.
1 0 1 0 – Well if I didn’t give it away in the beginning to you why does this happen?
The dictionary is storing the values by value not by reference for structs. This means the increment on the variable will only effect that instance. The dictionary has the previous referenced value. Then calling increment from the dictionary’s index has no effect.
This is a very basic understand you should have before ever using a struct. It is fundamental, but difficult to understand at first.
I must thank Eric Lippert for this example, as it comes from his stack-overflow answer on the topic.
For this puzzle, there is a little code snippet at the end that may help you in the future. The puzzle really isn’t super hard to figure out. Unfortunately, it is a either you know it or you don’t.
Note: Scroll selectively to not spoil the results.
Lets jump into it.
class Program
{
static void Main(string[] args)
{
Console.WriteLine(MyClass<string>.Method("Hello"));
Console.WriteLine(MyClass<string>.Method("World"));
Console.WriteLine(MyClass<char>.Method('!'));
Console.ReadLine();
}
}
public static class MyClass<T>
{
public static Guid Guid => Guid.NewGuid();
public static string Method(T item)
{
return $"{typeof(T).Name} {Guid} {item}";
}
}
What do you expect the output to be?
Space to avoid spoilers.
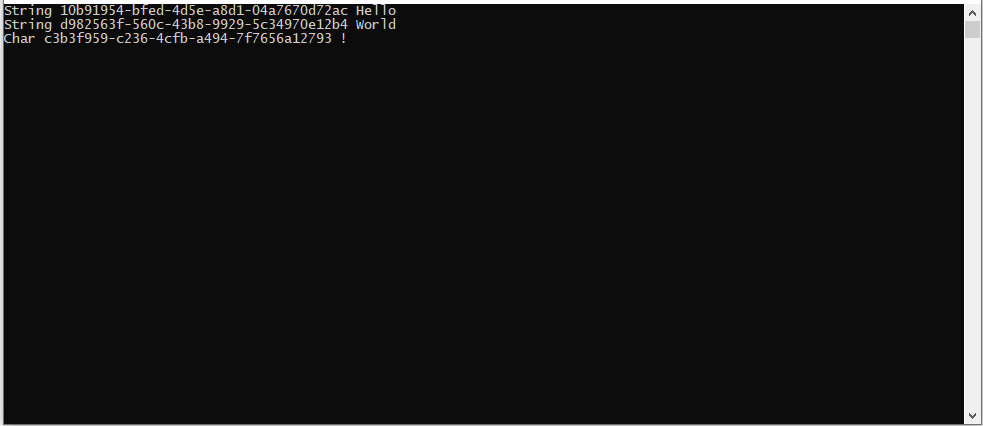
Nothing super surprising. Three different Guids are created, because the property is returning a new value every time. Let’s change the code so it doesn’t now.
Interesting Tidbit: Microsoft recommends properties to not be self changing. It recommends methods to be used instead of properties for values that can change without class manipulation. This is why Guid.NewGuid() is a method. Notably, DateTime.Now is a property but it is considered a design mistake.
class Program
{
static void Main(string[] args)
{
Console.WriteLine(MyClass<string>.Method("Hello"));
Console.WriteLine(MyClass<string>.Method("World"));
Console.WriteLine(MyClass<char>.Method('!'));
Console.ReadLine();
}
}
public static class MyClass<T>
{
public static Guid Guid { get; } = Guid.NewGuid();
public static string Method(T item)
{
return $"{typeof(T).Name} {Guid} {item}";
}
}
What do you expect the output to be now?
Space to avoid spoilers.
Now we get 2 different Guids. One for string and one for the char. Do you know why? Well most are not surprised by this behavior, but it is a different behavior that Java would produce. Java, or at least older versions of Java (I’m not 100% sure on current), would create a Type MyClass<T> then they cast the variable coming in and out as the Type when used. So there is only one definition of MyClass.
.NET though creates a Type specific for every generic used. This means there is a Type created at run-time for both string and char. .NET will create each method as they are used for the generic, specific for that generic. This means we actually end up with two static classes create. MyClass<string> and MyClass<char>.
Let’s build on top of this for a minute though.
class Program
{
static void Main(string[] args)
{
Console.WriteLine(MyClass.Method("Hello"));
Console.WriteLine(MyClass.Method("World"));
Console.WriteLine(MyClass.Method('!'));
Console.ReadLine();
}
}
public static class MyClass
{
private static Guid Guid { get; } = Guid.NewGuid();
public static string Method<T>(T item)
{
return MyGeneric<T>.Method(item);
}
private static class MyGeneric<T>
{
private static Guid GenericGuid { get; } = Guid.NewGuid();
public static string Method(T item)
{
return $"{typeof(T).Name} {Guid} {GenericGuid} {item}";
}
}
}
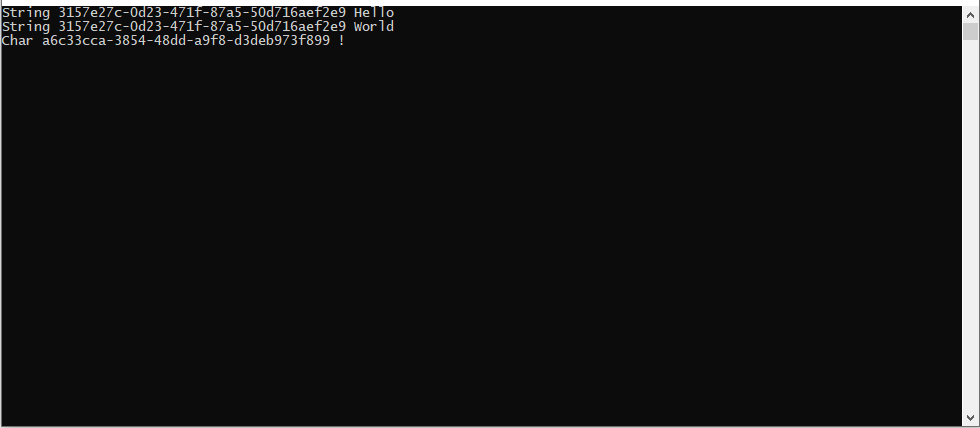
If we remove the generic from MyClass, keep the generic on the method, and create a sub class with a generic we can have both behaviors. Additionally, when calling the generic method we no longer need to specific the generic. Where before we had to on the class.
Personally, I will follow this paradigm when dealing with static generic members. It keeps the external usage simple. The output is as expected. Guid is defined once, GenericGuid is defined per type.
Although this is great at keeping your API clean it does have an additional side effect. It is faster than a dictionary where the key is Type.
As far as a simple test goes, this is just comparing the reading between a dictionary and a generic static variable.
class Program
{
static void Main(string[] args)
{
var watch = Stopwatch.StartNew();
for (var i = 0; i < 10000; i++)
{
GenericSubclass.Method<string>();
GenericSubclass.Method<object>();
GenericSubclass.Method<int>();
GenericSubclass.Method<DateTime>();
}
watch.Stop();
Console.WriteLine(watch.Elapsed.Ticks);
watch.Restart();
for (var i = 0; i < 10000; i++)
{
TypeDictionary.Method<string>();
TypeDictionary.Method<object>();
TypeDictionary.Method<int>();
TypeDictionary.Method<DateTime>();
}
watch.Stop();
Console.WriteLine(watch.Elapsed.Ticks);
Console.ReadLine();
}
}
public static class GenericSubclass
{
public static Guid Method<T>()
{
return SubClass1<T>.Guid;
}
public static class SubClass1<T>
{
public static Guid Guid = Guid.NewGuid();
}
}
public static class TypeDictionary
{
public static Dictionary<Type, Guid> lookup = new Dictionary<Type, Guid>
{
{typeof(int), Guid.NewGuid() },
{typeof(string), Guid.NewGuid() },
{typeof(object), Guid.NewGuid() },
{typeof(DateTime), Guid.NewGuid() }
};
public static Guid Method<T>()
{
return lookup[typeof(T)];
}
}
In my testing the Generic Subclass performs 10 times faster than the dictionary. This although is really negligible because the dictionary is still really fast. Both need to be measured in Ticks to even compare the two.
Personally I like the Static Generic Subclass, as Dictionary<Type, object> and lookup[typeof(T)] always felt strange to me.
There is something that actually makes a lot of sense with this pattern though. When using expressions, funcs, or actions, you can keep the generics for those while not complicating your API. Just a thought.
So instead of having a Dictionary<Type, object> and having to cast to let’s say Action<T> for a cache, having a Static Generic Subclass could keep your generic defined properly and you wouldn’t have to cast or do typeof.
I read a simple article today about a leadership principle Bezos believes in. It reflects the purpose of Part 1 and Part 2.
You really can’t accomplish anything important if you aren’t stubborn on vision, but you need to be flexible about the details because you gotta be experimental to accomplish anything important, and that means you’re gonna be wrong a lot. You’re gonna try something on your way to that vision, and that’s going to be the wrong thing, you’re gonna have to back up, take a course correction, and try again.
Jeff Bezos – 2016
There is some duality in this statement and this exercise for me. First, thing to understand is working through the details of my current vision state. Second, why didn’t anyone have course correction with this pattern?
What is important to me isn’t what pattern people use, but they can be successful for their first release all the way until the product’s last. From an Enterprise Architecture stand point, limiting immediate risk and ensuring longevity. More specifically can my current team deliver, and can I hire any junior developer off the street to maintain? If your current team cannot deliver anything maintainable, you need a new team.
This raises a grey area. Where something can be developed using something a-typical or a version behind or ahead the current recommend approach. The question that must be answered is, am I sure in 5 years someone fresh can still be productive in it?
There is another important concept here. If a development team had a hard time being successfully with a simpler solution, how can I believe recommending a different or more complicated would lead to success?
Don’t check box
Leadership check a box that they have something, and developers check a box that they did something. No-one confirms the desired outcome was actually achieved.
Two problematic leaders are the Buzz-word Architect, and the List-driven manager. Both have the same underlining flaw, they don’t evaluate what they are recommending is applicable or achieving a goal.
Side Story: I once took ownership of a product. During KT (Knowledge Transfer) from the previous architect, I was reviewing his code. He used the keyword dynamic, and I asked him why. It was new at the time. I don’t remember his specific answer, but I remembered thinking, he read some article and used it because of it being a buzz. It was loading the dynamic run-time and there was no reason for it.
Check-box developers are not innately a problem, leadership giving a fundamental task to check-box developer is a problem. Check-box developers are good at working in cookie cutter molds. If you tell a check-box developer to add a fundamental item, most likely they will add it and say it is done. They usually don’t confirm the goals are being achieved unless you specify them.
Forget Everything
At this point forget everything you know about whatever implementations you have used. If you are reading this with any bias you probably will not see the point. I’ve got many questions from the previous articles that were exactly opposite from what I was saying.
As a thought exercise, this is of course relevant to defending the repository pattern, but for me its understanding where things can go wrong.
Deconstruction before construction
Before using a pattern, one must deconstruct it’s purpose and define your goals. This is the step I performed that arrived me at the divergent Repository Pattern.
Purpose
Repository – Responsible for CRUD.
Unit of Work – Responsible for Scope.
Data Layer – Table Specific Functions
Business Layer – Domain, defining operation scope, and using CRUD.
Goals
Abstraction
Decoupling from ORM
Trying to achieve a percentage of re-usability
Providing a simpler facade for development
Providing a location for enhancements over the ORM
Testability
Code Quality
Reducing code duplication
Enabling developers
Extensibility
Ease of Use
If you read these goals and think, the Repository Pattern doesn’t achieve them, it’s probably because you didn’t list your goals before implementing.
Tweak for your needs
The reasonable man adapts himself to the world: the unreasonable one persists in trying to adapt the world to himself. Therefore all progress depends on the unreasonable man.
George Bernard Shaw
Be methodical, organize good resources, select best of class and adapt to your needs. Who cares if you follow a blog or msdn post specifically, if it leads you to a path that is undesirable. Don’t trust every resource, be skeptical of everything.
With something as core to your application and potentially other company applications, take your time do it right. Don’t worry if your definition of right is different from an online source. Only worry if your team has concerns. Your acceptance, is from the local development team not from which ever “Guru” wrote a blog post.
Exceptions
For me I do have a set of rules I will not violate, and it pains me greatly when I do. This isn’t typically concerning the specific pattern design, but designing itself. SOLID and Framework Design Guidelines are two things you try not to tweak.
That being said, nothing in finite. One thing I know I violate is a rule laid out somewhere in that book about interfaces. The rule states something like, ~Make sure to have one implementation in you assembly of any interface you design. This was problematic for this design.
Clarification on the proposed changes
Because a lot of people didn’t understand the design I suggested, and some actually found it useful, I wanted to clarify exactly what I was saying. (This is not a recommendation, this is problem solving.)
I want to make two things very clear in the design I laid out:
No Specific Repositories Per Type
No Custom Unit Of Work
IRepository
The generic IRepository is CRUD. It is implemented once per provider, not type. It uses IQueryable, not IEnumerable. There are two ways to enhance it’s capabilities extension methods and rules.
EntityRepository
For clarity on how this design actually should function 99% of the time, the EntityRepository is sealed. It is vanilla, it isn’t special. Only thing different is, it has to ask EntityUnitOfWork for the DbContext, or have a mechanism to share the DbContext.
IUnitOfWork
IUnitOfWork is responsible for Start, Save, and End. It does not have each Repository in it, it does not have any additional concerns. It implements IDisposable to trigger end.
Rules
The Rules Service is an event aggregator, functional paradigm, publish subscribe pattern (Not Cloud), queue or something custom. It’s purpose it to apply rules to different types. For example an entity is being updated, it is going to apply all rules for the entity type any any interface the entity implements.
An easy conventional rule to understand is Soft Delete. You would define a common rule in the framework. The Cross App Convention would be an interface for ISoftDelete. Your Cross App Rule would specify how to handle this. On Delete it would undo the delete, mark IsDeleted to True and update instead. On Read the rule would add a predicate to exclude deleted items.
You can also have Repository Extensions in the Rules DLL, but they are rare. For example: public static IQueryable<TEntity> QueryIncludingDeleted<TEntity> (this IRepository<TEntity> repository) where TEntity : ISoftDelete
One thing that is powerful with Rules, is that a Framework update or adding a DLL with a container, can adjust your data access behavior. Your Rules are not coupled to EF and it is powerful to add functionality without changing your code. IE: adding a new rule across your micro-services doesn’t require re-writing your micro-services.
EntityUnitOfWork
Entity Unit Of Work is pretty basic. It caches a DbContext once created, can dispose, and has a Save method.
For EF specifically, the rules should be applied just before Save. Doing it earlier has the chance to miss things. This needs to be handled in EntityUnitOfWork.
I have also overridden the ToString method on this class in the past. In Debug it would output pending changes and submitted changes.
Application Data Layer
The data layer does not have custom implementations of Repositories. It does not modify the UnitOfWork in anyway, it doesn’t even use it. Did I say this enough yet?
Repository Extensions
Although I agree it is a bit strange, as generic extensions are rarely used. But this is the only work around without creating specific interfaces and classes for the Repositories. Remember you are exposing the Queryable object, so any data layer queries that are not specific to a business operation can go here. Pretty much a query reuse point.
If your arguments to these functions are of Type Expression or Func, you probably are doing something wrong. IQueryable is exposed.
App Specific Rules
Anything that doesn’t fit into a common rule, things that might be table specific or domain specific should be implemented in the application data layer.
Business Layer
Here of course you should be still doing domain driven design. The business layer is responsible to determining the scope of the business operation, IE the UnitOfWork. It will through DI resolve the UnitOfWork, and IRepositories<T>. IRepository<T> will have the custom extension methods available, and since IQueryable is exposed, you can still project to your domain object. Additionally you can map from your domain object into your entities.
Here is a vanilla code example and UML diagram
using(var unitOfWork = _locator.GetService<IUnitOfWork>())
{
var repository = _locator.GetService<IRepository<Person>>();
var query = repository.CustomQuery(....);
repository.Insert(...);
unitOfWork.Save();
}
Potential changes from Part 1
One thing that I think makes sense as a change from the original write-up from Part one is restructuring the DI. The EntityUnitOfWork should take in the DbContext in the constructor, and share it between the EntityRepositories. The generic TDbContext can then be removed. This only works if you only ever plan to have 1 DbContext in an AppDomain. It may get confusing otherwise, but I guess you can use named instances.
Additionally the need for a UnitOfWorkManager seems to be limited. As long as you can share an instance of the UnitOfWork per operation somehow its fine. I like this to be implicit instead of explicit. Once you are in a UnitOfWork everything should be using the same context. This although may have problems with the newest version of EF as they automatically dispose of the context… wtf.
Potential issues with this design
Besides everyone hating you because they believe they know best. And, besides all the none issues that people will typically argue there are a few flaws I didn’t discuss.
A UnitOfWork within another UnitOfWork. Not hard to solve, I just didn’t for you.
The need for a IAdvanceRepository with Undo functions or other operations.
Configuring your container correctly.
It’s a fucking blog post with pictures of monkeys.
Conclusion
Do what’s right for you and your team. Don’t be scared to change something to fit your needs.
If your interested in more information, I talk about adding Conventions with EFCore as well. Soon, I’ll table about adding rules to your conventions. These posts though, are not targeting a Repository Pattern specifically.
I think it is fun to find abnormal behavior in the language you use, but C# is a language that doesn’t have many abnormal behaviors. I plan on posting a few that I know, and hope to find more. This is my first puzzle and it stems back 10 years for me. I once spent some time reviewing every keyword in C#, and this was something I came up with from that.
Note: Scroll selectively to not spoil the results.
static void Main(string[] args)
{
try
{
var lorem = "lorem ipsum dolor sit amet, consectetur adipiscing elit. Nunc rutrum porttitor nibh a imperdiet. Cras blandi ";
var first = lorem[0];
Console.WriteLine($"First Character: {first}");
lorem = lorem.Remove(first);
Console.WriteLine(lorem);
}
catch (Exception e)
{
Console.WriteLine(e.GetType().Name);
}
Console.ReadLine();
}
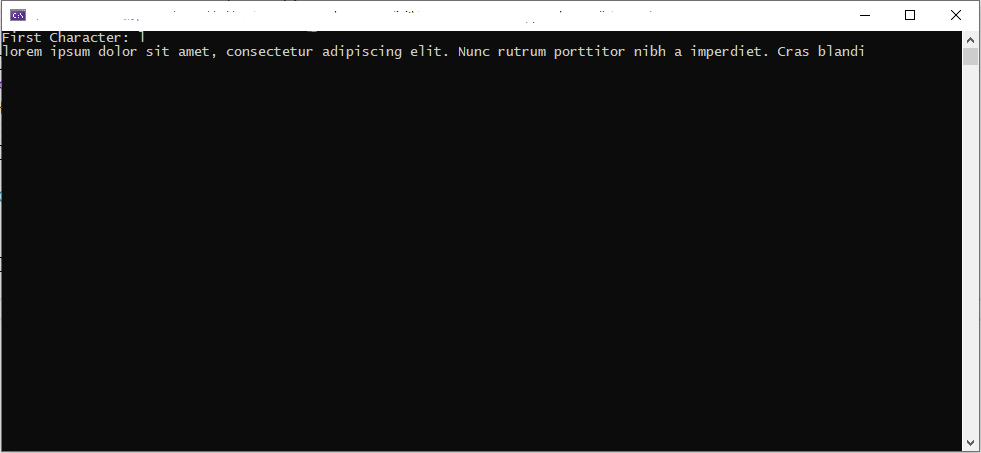
Pretty basic function, getting the first character from the lorem string. Then we are removing the first character from the string.
What do you expect to happen?
Space to avoid spoilers.
It outputs ‘l’ for the first letter, but also outputs the lorem string without removing the ‘l’.
Umm OK.
Now lets change “lorem” to “zorem”.
static void Main(string[] args)
{
try
{
var lorem = "zorem ipsum dolor sit amet, consectetur adipiscing elit. Nunc rutrum porttitor nibh a imperdiet. Cras blandi ";
var first = lorem[0];
Console.WriteLine($"First Character: {first}");
lorem = lorem.Remove(first);
Console.WriteLine(lorem);
}
catch (Exception e)
{
Console.WriteLine(e.GetType().Name);
}
Console.ReadLine();
}
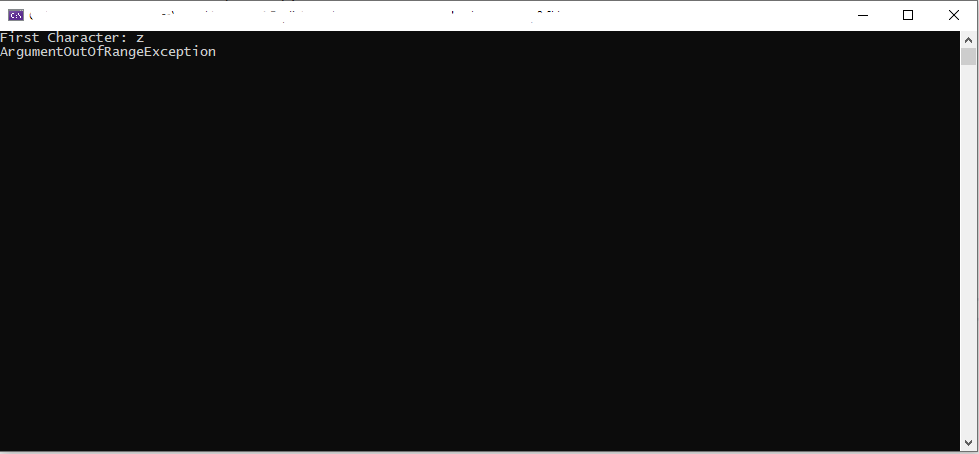
What do you expect to happen now?
Space to avoid Spoilers.
It outputs the letter ‘z’, but now it throws an ArugmentOutOfRangeException. Any idea on why? Take a second to read over the code and see if you can figure it out.
Space to avoid Spoilers.
Well this is actually pretty easy to understand. The “first” variable is of course a character, but the “Remove” function isn’t what it seems. It is actually String.Remove(int startIndex). There is a implicit conversion between the char and int native types that automatically converts to a char to an int.
int ascii = 'a';
This above line compiles and works. What happens is your actually calling lorem.Remove(108) for ‘l’ and lorem.Remove(122) for ‘z’. The string is actually 108 characters long, so the first call would remove the trailing space. The second call with ‘z’ throws an ArgumentOutOfRange because the string isn’t 122 characters long.
Interestingly, although you can implicitly convert a char to an int, you cannot do it the other way around. Converting a int to a char is explicit like so:
char character = (char)122;
Hope you enjoyed this little puzzle. I’ll post more soon.
Typical arguments are going to be around these factors:
Restrictiveness
Performance
Flexibility
Complexity
Utility
Purpose
I find these arguments pretty lackadaisical. Anyone misusing a pattern with a bias can come up with a talking point for each one of those.
Concern #1 – It limits EF/ORM
It doesn’t have to. Its a pretty hard headed statement to say Repository only. It should be Repository First. If what you are trying to achieve needs something from your ORM specific expose it.
Don’t expose it from your Framework.Data.dll which contains the the Repository Pattern though. Make it extension methods or something specific in Framework.Data.EF.dll. This way if you ever change the implementation and remove that dll, you will get errors everywhere that used something custom.
This gives you a high level of re-usability between ORMs if you were ever to switch. Although, I couldn’t imagine I can see that happening anytime soon. I did although believe in many frameworks that are now completely deprecated.
Concern #2 – Queryable Vs Enumerable
Some Repository patterns will return Enumerables due to the desire to be flexible with other frameworks. This causes them to be slow and inefficient. Just return Queryables, you can always use .AsQueryable() on an Enumerable if needed.
Concern #3 – Domain Driven Design
I did not cover this specifically, and may cover this in the future. Repositories are built off of the Entities, but a true business layer would return domain objects. In my opinion, the business layer needs tools to use the Repositories and help you adapt to your domain objects. Using tools such as AutoMapper can adapt the domain objects coming in, and can project the objects with-in the query coming out.
Projection is something developers usually don’t use, but is extremely powerful. Using a projection, you can select your domain object directly from the query eliminating the need to even materialize the entity in the data layer. I personally do not like AutoMapper’s default for this, and usually will write my own custom expression tree to achieve this.
Concern #4 – Additional Complexity
This is a legitimate concern, but the larger the project you are doing the more it makes sense. If you’re working for a start-up then don’t worry about patterns.
What’s complexity to me is constantly using multiple steps to do CRUD operations, not centralizing common code and manually having to apply conventions through-out your code.
I was on a project and approaching the end of development. The BAs stated they needed a new functionality that they forgot to ask for. It was that anytime for any table a SSN was changed, we needed to insert a row into a table an trigger a batch operation overnight. SSN was used in a couple dozen tables, we already had 10 million lines of code that already have been QA tested.
This was a simple to add this feature, and I was told in the past similar projects it took months to add this feature. It took a day with this pattern. The code was decoupled and centralized.
Concern #5 – Querying multiple tables
If you are using Queryables out of your repositories, there is no reason why you cannot join or use multiple repositories in a single query. This is an implementation concern or design. The repository pattern does not stop you from doing this.
Concern #6 – I’m never going to change my DB or ORM
I wish my crystal ball was that clear. If you own your company, if you have a strong foot hold over technology in your company maybe you can make that claim with some certainty.
I was consulting to a client. First thing we did was a database evaluation: Postgres vs Sql Express. We landed on Sql Express. 75% into development we released our first installer, yes a thick client. The complaints started coming in. This takes too long to install, the file size is too big, etc.
I brought in a two core 1.3Ghz netbook, because legit we couldn’t find a machine close to our minimum spec. I turned off one core, and installed the application on it: 2 minutes.
“Well it took 10 minutes on mine”, said the PO.
Well stop looking up porn on your work computer, I thought.
The PO continued his debate, “Well the file size is too big, we need people in remote areas using 56k modems to be able to download it.”
The file size was 300MB. I took a deep breath, “Don’t you already ship out CDs to those places?”
“Well yeah.”
After days of back and forth I finally nailed down the real problem. One of their clients refused to accept a product with Sql Express, and there was no talking them out of it. The PO was trying to blame the tech team and save face.
We tested several different types of databases since they also had a ridiculous security requirement of entire database encrypted at rest. All of this was possible because of the Repository pattern, and the switch was actually pretty lightweight in the end. So don’t tell me no-one ever change their database, it was the bane of my existence for a month. This entire episode happen in 2017, 56k modems and P3 1Ghz minimum spec.
Conclusion
What I know is, this pattern has been blacklisted by most, but I believe that is because of their past implementations. Most will skim this, discount it prematurely with bias, and not understand the underlining purpose.
The Repository Pattern is on the edge of death. Not because it couldn’t work, because so many people have added their own constraints to the pattern and failed to step back and solve the problems. The problems really are not hard to solve.
Are the tech “Gurus” we are listening to creating the best content for us? Most say something is bad because of abc, my implementation was junk, etc. They recommend another approach, but never evaluate solving their problems. Let’s just always move to the next shinny thing. That logic to me is toxic, cause who is to say the next shinny thing won’t have it’s problems that won’t be addressed.
If you are doing the Repository Pattern and like that style, don’t adapt everything here. I wrote this as an example. Their maybe concepts here that can help you. If you want to know more about how I solved these problems in the past, I can create some more code for you.
Pick your favorite pattern and search for it followed by “Anti-Pattern”. Some blogger somewhere will misuse that pattern and tell you why it is bad.
Yes some patterns don’t achieve everything we desire in quality code today, but that doesn’t mean they are Anti-Patterns. If a pattern achieves what it sets out to do semi-efficiently without any ill side effects, it isn’t an Anti-Pattern.
Using the word “Anti-Pattern” is dismissive and toxic when used improperly. Kind of sounds like an Anti-Pattern huh? Well it is. The Blowhard Jamboree management Anti-Pattern outlines tech experts who are technical bullying teams into their views.
Calling patterns Anti-Patterns is the equivalent of tech click-bait online. In person, its abrasive and counterproductive. Have a conversation, discuss how it could be applied, out-weigh the side effects.





 (no Unicode)
(no Unicode)  : (no Unicode)
: (no Unicode) 


 : (no Unicode)
: (no Unicode) 
















You must be logged in to post a comment.